 ITI Capital
ITI Capital 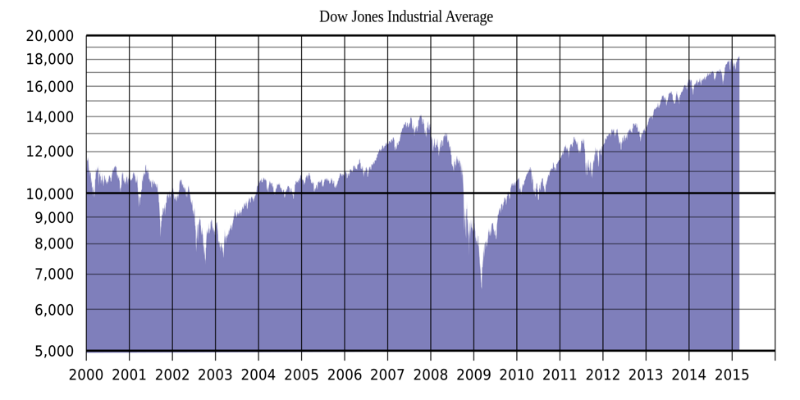
Прогнозирование волатильности с помощью анализа мнений инвесторов
Исследователи Технологического института в индийском городе Коимбатор опубликовали работу, посвященную использованию механизмов анализа Big Data для определения тональности общественного мнения использования этих данных для создания прогнозов движений на фондовом рынке.
В частности, анализировались сообщения и отзывы, которые инвесторы и трейдеры оставляли на сайтах бирж и финансовых организаций.
В процессе анализа необходимо было собрать данные, а затем выделить из них маркеры, указывающие на то, положительное или негативное это высказывание. При этом необходимо учитывать особенности естественного языка, которые необходимо учитывать для избежания ошибок — к примеру, фраза «неплохо» является положительной характеристикой. 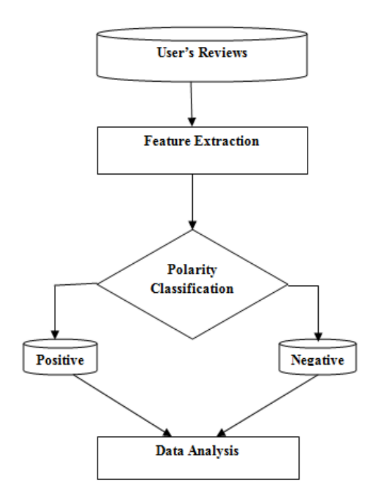
Подобную классификацию можно проводить различными способами — на уровне документа, предложения или фразы. Для этого также могут применяться различные механики машинного обучения — например, алгоритмы для обучения с «учителем» и без учителя, которые противопоставляют друг другу.
В последнем случае для опрееделения общей тональности высказывания часто используют анализ лексикона — система ищет слова, которые выражают мнение (opinion words), например прилагальные.
В случае же обучения с учителем используются обучающие выборки, в которых содержатся входные данные и желаемый результат анализа. Для сравнения этих данных можно использовать наивный баейсовский классификатор или алгоритм опорных векторов.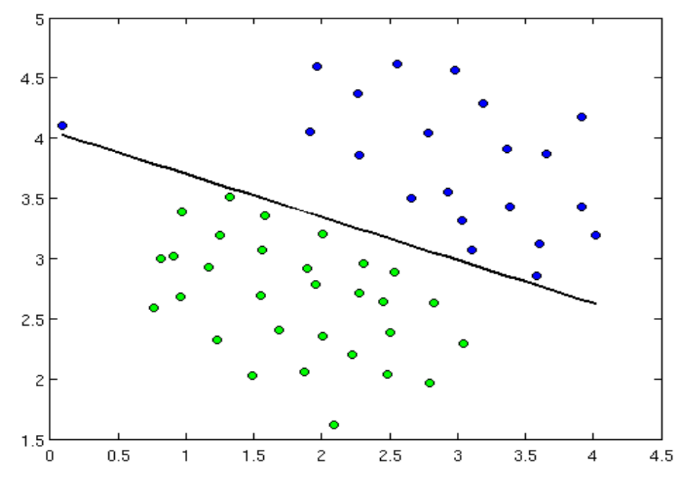
Линейный классификатор по алгоритму опорных векторов
Данные о тональности высказываний инвесторов также сопоставляют с историческими данными для определения финансовой волатильности — после этого можно выработать прогнозы о том, какой эта величина может быть в будущем. Под волатильностью здесь понимается изменение стоимости финансового актива за определенный период времени.
Для анализа временных рядов применяются модели авторегрессионной условной гетероскедастичности (ARCH) — они предназначены для анализа процесса кластеризации волатильности на финансовых рынках. Которая выражается в том, что периоды высокой волатильности сменяются периодами низкой волатильности. При этом средняя волатильность остается относительно стабильной — все это позволяет прогнозировать, какой волатильность может быть в будущем.
При этом, ARCH-модель предполагает зависимость условной дисперсии только от квадратов прошлых значений временного ряда. Эта модель была обобщена, когда было выдвинуто предположение, что условная дисперсия зависит также от прошлых значений самойсебя — в итоге появилась модель GARCH (Generalised ARCH).
Схема работы
Исследователи разработали систему, которая применяет алгоритм опорных векторов к GARCH-модели для предиктивного анализа ситуации на фондовом рынке. Работает она по следующей схеме:
- В начале с популярных финансовых сайтов скачиваются обзоры аналитиков, отзывы инвесторов и трейдеров, а также логи их открытых чатов в процессе торгов в текстовом формате, кроме того, в систему загружаются новости с сайтов компаний, чьи акции торгуются на биржах;
- С помощью алгоритма опорных векторов определяется тональность высказываний (эксперименты показали, что этот алгоритм позволяет создать более точную классификацию, чем в случае применение байесовского классификатора);
- Также за тот же период времени загружаются исторические данные значений анализируемого фондового индекса — эта информация используется для вычисления волатильности по модели GARCH;
- На основе полученных данных генерируются прогнозы тренды волатильности для отдельных акций (для акций небольших компаний модель работает лучше, чем для крупных).
Система для выбора перспективных акций на основе данных Twitter
Исследователи из Лондонского Imperial College в свою очередь опубликовали рассказ о создании инструмента для анализа публикаций в соцсетях и выявления корреляций этих данных с трендами фондового рынка для формирования портфолио перспективных акций.
Различные исследования, в том числе ученых Стэнфордского универститета, демонстрируют наличие корреляции индекса Доу-Джонса и настроений пользователей Twitter: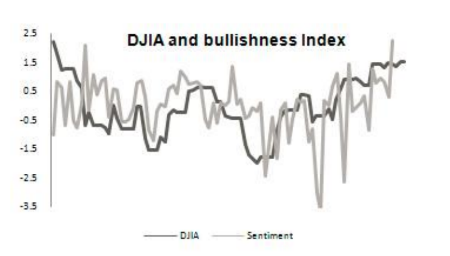
Анализ этой информации позволяет вырабатывать прогнозы относительно будущих движений цен. Английские исследователи создали приложение, которое скачивает твиты, которые связаны с компаниями, входящими в индекс S&P 500, запускает Hadoop джоб для создания агрегированной оценки тональности для каждого высказывания и набора акций (портфолио), а затем ранжирует портфолио, чьи оценки позитивной тональности выше, чем у других.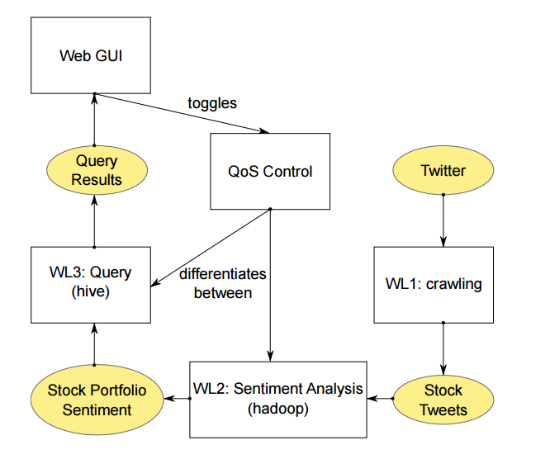
Архитектура приложения
Демо-система работает в кластере Hadoop 1.1.2 и IBM GPFS 3.6. Каждый узел оборудован восемью чипами Intel Xeon 2.5 GHz CPU, 8 GB памяти и 250 GB хранилища, ОС — RedHat Linux.
По словам создателей приложения, инвесторы могут использовать его для выбора наиболее перспективных в данный момент акций для торговли — этот инструмент не предназначен для точного предсказания цен акций, но помогает выбрать те, по которым можно ожидать движения в ту или иную сторону.