 Anthony Toomy1
Anthony Toomy1 Всем привет! В данной статье я постараюсь рассказать о том, как можно сэкономить кучу времени, нервов и зрение, перебирая тысячи спредов пар, в попытке отсортировать ненужные нам спреды. Но для начала давайте вспомним о чем писалось в прошлых статьях:
1. Коинтеграция в парном трейдинге
3. Парный трейдинг. Акции для пар
4. Парный трейдинг: пара акций, корреляция, коинтеграция спреда, инвестиционный портфель (Клевцов Антон)
Тем кто не читал, настоятельно рекомендую. В этих статьях описана сама концепция парного трейдинга, почему коинтеграция а не корреляция, что такое спред и как его строить.
Ну а теперь поговорим о возможных фильтрах спредов, а точнее о фильтре "красоты" спреда, в свое время мы его называли именно так)
Измерение степени коинтеграции
В первой статье я уже рассказывал про коинтеграцию и о её важности. Настало время познакомится с ним с прикладной точки зрения.
Для чего нам рассчитывать коинтеграцию? Мы уже знаем, что строя спреды между акциями, мы хотим увидеть в них какое то преимущество и понимание. Расчет коинтеграции поможет нам отфильтровать хаотичные спреды, которые ничем не отличаются от непредсказуемых графиков стоимости акций компаний.
Как же упростить поиск красивых спредов?
Для оценки степени коинтеграции между временными рядами существует ряд математических методов, одним из базовых и самых эффективных является Расширенный тест Дики Фуллера (ADF test). Вдаваться в математическую составляющую в рамках этой статьи не будем, т.к. для понимания принципа необходимо знать более простые модели и понятия из эконометрики. Но не стоит забывать что живём мы в эру информационных технологий и любая математическая модель может быть автоматизированная в среде программирования. Из последних я выделяю MatLab и R project, но предпочел последний. Поэтому все куски кода, которые я буду выкладывать в этой и последующих статьях будут относится именно к языку R.
Построим спред пары BMR/OFC:
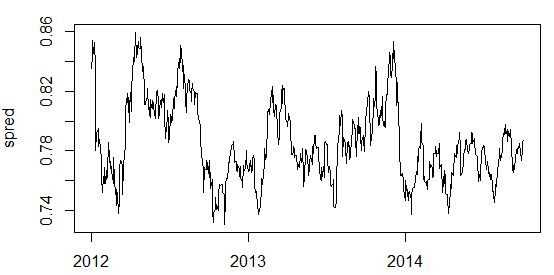
Видим очень даже неплохой спред. Данный спред прошел АДФ тест с отличием, значение p.value на выходе получилось равным 0.01, что может говорить о принадлежности данного спреда к стационарному на 99%. Значение p.value это коэффициент, который показывает вероятность того, что спред не стационарный. В нашем случае значение коэффициента равно 1%, значит с вероятностью 99% утверждаем что данный спред нам подходит. Стационарным принято считать временной ряд, если значение p.value меньше либо равно 0.05, т.е. 5%. Но из своего опыта могу сказать, что АДФ тест не идеален и частенько приписывает хорошим спредам высокое p.value, а плохие спреды относит к стационарным.
Код для расчета p.value:
library(timeDate)
stock1=get.hist.quote(
instrument = "BMR",
start = "2012-01-01",
end = "2014-10-01",
quote = "AdjClose",
retclass = "zoo",
quiet = TRUE,
drop = FALSE)stock2=get.hist.quote(
instrument = "OFC",
start = "2012-01-01",
end = "2014-10-01",
quote = "AdjClose",
retclass = "zoo",
quiet = TRUE,
drop = FALSE)spred=stock1/stock2
p.value=adf.test(spred)$p.value
Функция get.hist.quote качает цены закрытия дня, скорректированные на дивиденды и сплиты, данные берет с yahoo finance. Параметры start и end указывают период скачиваемой даты. Параметр instrument устанавливает название тикера необходимой акции. Последние две строчки строят ratio spred и определяют значение p.value.
Что бы вас убедить в работоспособности АДФ теста, построим пару SPY/AAPL:
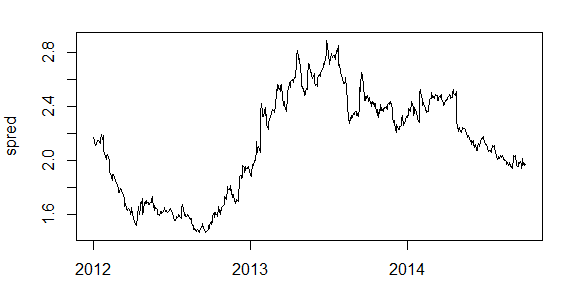
Согласитесь, ловить здесь нечего, что и показал нам тест: значение p.value = 0.9, т.е. 90% что спред не стационарен, думаю спорить никто не будет))
Остальное за каждым из вас) К этому коду надо написать цикл, который будет строить все возможные пары и определять их уровень коинтеграции. Могу сказать, что из нескольких тысяч пар, даже может из десятка тысяч, отфильтруется порядка 97-98%)) Хороших пар не так уж и много.
Фильтр спредов N2
Есть еще один вариант неплохого фильтра для спредов пар. Я его придумал не так давно, сильно его не опкатал еще, но работает он очень хорошо)
Вспомним, что финансовый временной ряд можно представить как совокупность Винеровского и Орнштейна-Уленбека процессов. Идея фильтра лежит именно на данной аксиоме: стационарный спред мы получим в случае, если трендовая составляющая в первой и второй акциях будут максимально похожи, тогда останутся только стационарные составляющие, спред между которыми мы и получим.
Разберем рисунок:
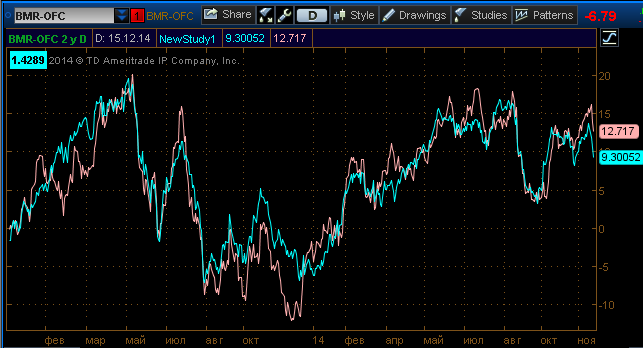
Мы построили два графика акций (BMR и OFC) приведенные к процентам.
Далее построим скользящие средние к каждому:
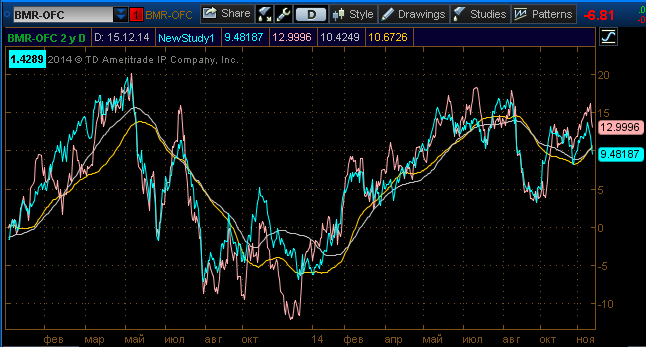
И видим, что тренды (скользящие средние) у данных акций практически совпадают. Когда мы построим спред между ними, эта трендовая составляющая исключит сама себя и мы получим спред между стационарными составляющими, которые распределены вокруг скользящих средних.
О том что спред между данными акциями стационарен вы можете убедится выше.
Теперь осталось данную модель интерпретировать в какой либо показатель. Я это сделал путём нахождения среднего арифметического абсолютной разницы между скользящими средними: (Sum|SMA1-SMA2|)/(Chart_period-sma_period). Получили некий показатель (назовем его t.value), который указывает среднюю абсолютную разницу между скользящими, соответственно чем она меньше, тем более схожа средняя составляющая у акций и тем более стационарен спред между ними. Проведя ряд испытаний, я выявил, что у неплохих спредов t.value не более 10, у хороших не более 5, у отличных не более 3х. Период сглаживания я использовал 50, с другим значение t.value будет другим и каким значениям будет соответствовать хороший спред - неизвестно. Но я много с ним не практиковал еще, поэтому диапазон значений может изменять под собственный вкус. Например t.value спреда BMR-OFC равен 1.43, а у SPY-AAPL равен 23.
Код, для расчета t.value для R:
filter = function(a,b,smooth_period,chart_period)
{library(TTR)
a=a[1:chart_period]
b=b[1:chart_period]
a=a/a[1]*100
b=b/b[1]*100
ema.a=EMA(a,smooth_period)
ema.b=EMA(b,smooth_period)
t.value=sum(abs(ema.a[smooth_period:chart_period]-ema.b[smooth_period:chart_period]))/(chart_period-smooth_period+1)
return(round(t.value,2))}
Где a - цены первой акции, b - цены второй акции, smooth_period - период скользящей (рекомендую 50), chart_period - длинна вашего графика.
Код для thinkorswim:
def Data1 = close(GetSymbolPart(1));
def Data2 = close(GetSymbolPart(2));
def kf = close(GetSymbolPart(1))[500];
def kff = close(GetSymbolPart(2))[500];
def bn = BarNumber();
def hbn = HighestAll(bn);
def bn_diff = hbn - bn;
def kf1 = GetValue(kf, -bn_diff);
def kf2 = GetValue(kff, -bn_diff);
def Data11 = (Data1/kf1-1)*100;
def Data22 = (Data2/kf2-1)*100;
def av1 = average(Data11,50);
def av2 = average(Data22,50);
def minus = sum(AbsValue(av1-av2),450)/450;
addLabel (yes, minus ,color.cYAN);
По неизвестным мне причинам, у некоторых пользователей не работает функция GetValue(), которая является неотъемлемой частью кода. Поэтому если у вас работает - отлично, если нет - вам не повезло(
Сам код отображает в верхнем левом углу (см. рисунок выше) значение t.value, при этом в области для тикера акции должна быть введена пара (ticker1-ticker2).
Ну вот собственно и всё, как фильтровать пары математически, сохраняя зрение и нервы, я рассказал, остальное за вами :)
Комментарии, вопросы и критика приветствуются. Ждем дальнейших выпусков :)